Q&A: On the frontiers of speech science

Speech is a human super power.
If your friend tells you they dreamed of a rainbow sloth hang-gliding over Mount Rushmore, you’re getting privileged access to the contents of their minds in a way no other animal can share. It’s not far from telepathy, but we do it with ease. This is particularly amazing because speech is so full of distractions, ambiguities, side-tracks and talking over each other — but our brains elegantly and effortlessly decode these chaotic soundwaves into a sense of shared understanding.
Wu Tsai Neuro’s newest faculty scholar, Laura Gwilliams, uses the latest brain recording and machine learning techniques to decipher how the human brain solves this remarkable challenge.
Gwilliams, who is co-appointed with Stanford Data Science and the Department of Psychology, with a courtesy appointment in Linguistics, brings a wealth of experience to this thorny problem.
After studying linguistics at Cardiff University, she became interested in neuroscience as a master’s student at the Basque Center on Cognition, Brain and Language in the Basque Country (Northern Spain). Later, as a graduate student with Alec Marantz and David Poeppel at NYU, Gwilliams used subtle electromagnetic signals recorded from the brains of research participants to demonstrate that listeners’ brain circuits can hold onto speech sounds for many seconds, enabling re-interpretation of speaker’s words based on later information. Remarkably, the brain flexibly adapts to the complexity of speech, efficiently holding on to more information only as needed.
Most recently, as a postdoctoral scientist in the lab of Edward Chang at UCSF, Gwilliams delved deeper into the brain circuits of language comprehension, working with patients with medically implanted electrodes for epilepsy treatment. In a study published in Nature on December 13, 2023, Gwilliams and UCSF colleagues were among the first to use revolutionary high-resolution Neuropixels electrodes in human subjects to map the contributions of individual neurons to speech comprehension.
Drawing on her expertise in linguistics, psychoacoustics, machine-learning analyses, and human brain recordings, Gwilliams aims to enhance our understanding of how our brains process speech at multiple levels — from individual speech-sensitive neurons to brain-wide networks that let our species share our ideas and understanding with one another.
We spoke to Gwilliams about her goals for her new Stanford lab. The conversation has been lightly edited for length and clarity.
What might people be surprised to realize about how we understand spoken language?
There’s a big contrast between how easy it feels to verbally communicate, and what a hard computational problem it is for the brain to solve. Because language is something we engage in constantly, people underestimate how complicated it is. It happens automatically without any real thought or effort, but the brain needs to go through a lot of complex transformations in order to turn sound into meaning.
You can appreciate this when you look at automatic speech recognition systems, which have historically really struggled with this transformation. In order for modern artificial systems to have anything like human performance, they have to have ingested multiple human lifetimes of speech to get anywhere close to what a human brain can do. In contrast, you can say something to a child once and they’ve got it.
How did you come to study the neuroscience of speech?
I grew up on the Welsh/English border and started out studying theoretical linguistics at University – learning how language is structured and what repeated motifs you can observe across cultures. That systematicity was fascinating to me. Our intuition about language is that someone speaking Finnish sounds completely different from someone speaking English, but with linguistic tools you can realize that at their core most languages are not really that different.
I got interested in why that is — what gives languages their common structure? Well, what’s common to languages is that they are all created by human beings with our common cognitive abilities and limitations. This got me very interested in the neural side of language.
I started to transition over to neuroscience while doing a masters degree at the Basque Center of Brain, Language and Cognition in San Sebastian, Spain. I was drawn to Basque because it’s what we call a language isolate, not related to any other living language. It’s also our also oldest living language – even older than Latin. From a linguistics point of view, Basque is also interesting because of its extreme use of morphemes – parts of words like ‘-s’ and ‘-ment’ and ‘-er’. In English, these tell you things like whether a speaker is referring to one object (“hat”) or multiple objects (“hat-s”). In Basque, morphemes that tell you things like who is speaking, who is being spoken to, who is in possession, what is the source of motion, and lots of other details. Basque linguists like to joke that all that’s missing is a morpheme that specifies what a speaker had for breakfast!
Your research focuses on how we perceive language. What progress has the field made on this question in recent years?
I like to think that there have been three primary directions of progress in this field.
One is understanding what representations the brain generates when there’s a speech input. What are the units of language — syllables, morphemes, words, or concepts — that the brain extracts from speech to form a bridge between sound and meaning? The majority of progress has been in this area.
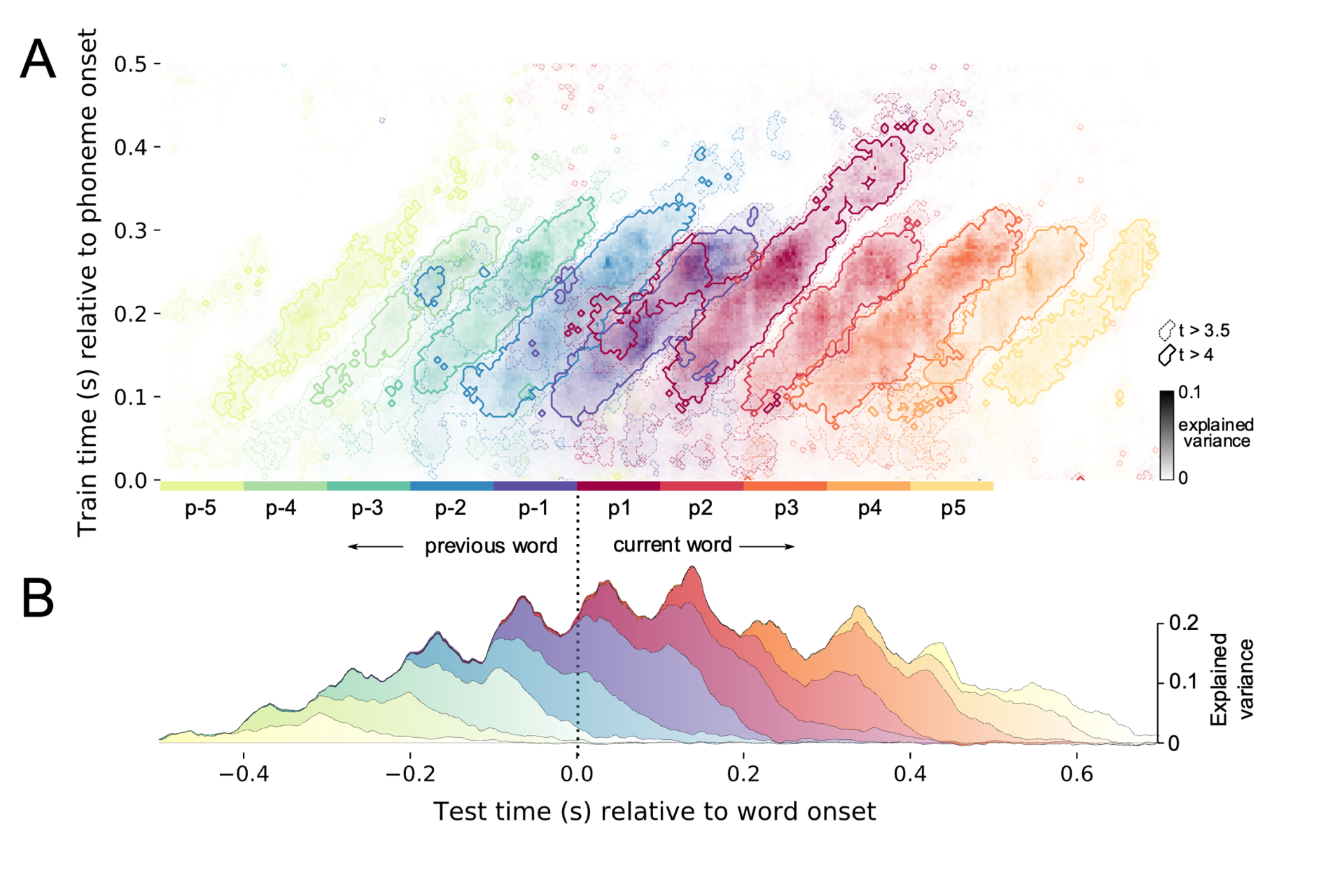
Second is the question of what computations the brain uses to create those representations and manipulate them. Maybe the brain needs to filter incoming signals in a certain frequency range. Maybe it needs to maintain certain information over time. Maybe it needs to add concepts together, like “red” and “boat” to create the concept of “red boat”. This is crucial, but much harder to get hold of analytically than the first question, so there has been less progress in that regard.
The final question has to do with information flow — the order with which all of these operations happen. For example, do you first get a general gist of meaning and then fill in the details of specific speech sounds? Or do you first figure out the details of speech sounds and then derive a semantic outcome? This is also one where there’s still a lot for us to learn.
What have you been learning about these questions through your own research?
One thing that’s great about having a background in linguistics is that linguistic theorists have been around for a long time, developing ideas about the core structures across different languages. This serves as a nice hypothesis space from which to study different potential brain representations as a neuroscientist.
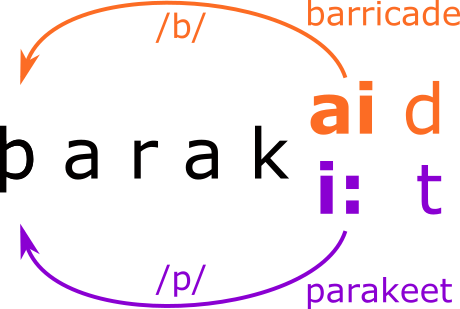
One of the things we’ve learned is that some linguistic theories posit representations that turn out to actually map on to what we see in the brain. For example — words are made up of morphemes — like the components of the word “disappears” are “dis” “appear” and “s”. We have evidence that these kind of building blocks of meaning and structure seem to be important to how the brain processes speech.
Another thing we’ve learnt is that the brain seems to prefer redundancy over sparsity. The brain creates a lot of representations that are quite similar to each other, which are generated in parallel and maintained for a long period of time. If I say, “The cat sat on the mat and enjoyed the sun going through the window,” that probably took three seconds to say, and your neural representation of the “c” in cat — as well as the concept of “cat” — probably stayed active for full time. This is a discovery I was fortunate to contribute to as a graduate student at NYU.
Through my work I’ve been trying to push forward a more naturalistic approach to the study of speech. A lot of work until very recently has used quite artificial paradigms — presenting individual words, one at a time. This can answer some questions, but we’re never going to be able to understand things like how past components of speech are carried forward in time to inform future understanding. I think only through naturalistic approaches — like presenting whole narrative stories — will it be possible to expose and explore the full complexity of language processing and illuminate how the brain constructs complex, novel meanings from speech sounds.
One big reason I’m excited to join the Wu Tsai Neurosciences Institute at Stanford is the opportunity to collaborate with leading researchers across multiple fields to understand how other aspects of our brain interact with language. For instance, what format is linguistic information maintained in? Acoustic, semantic, something else entirely? How does memory intersect with language? These are questions that need a lot more pursuit.
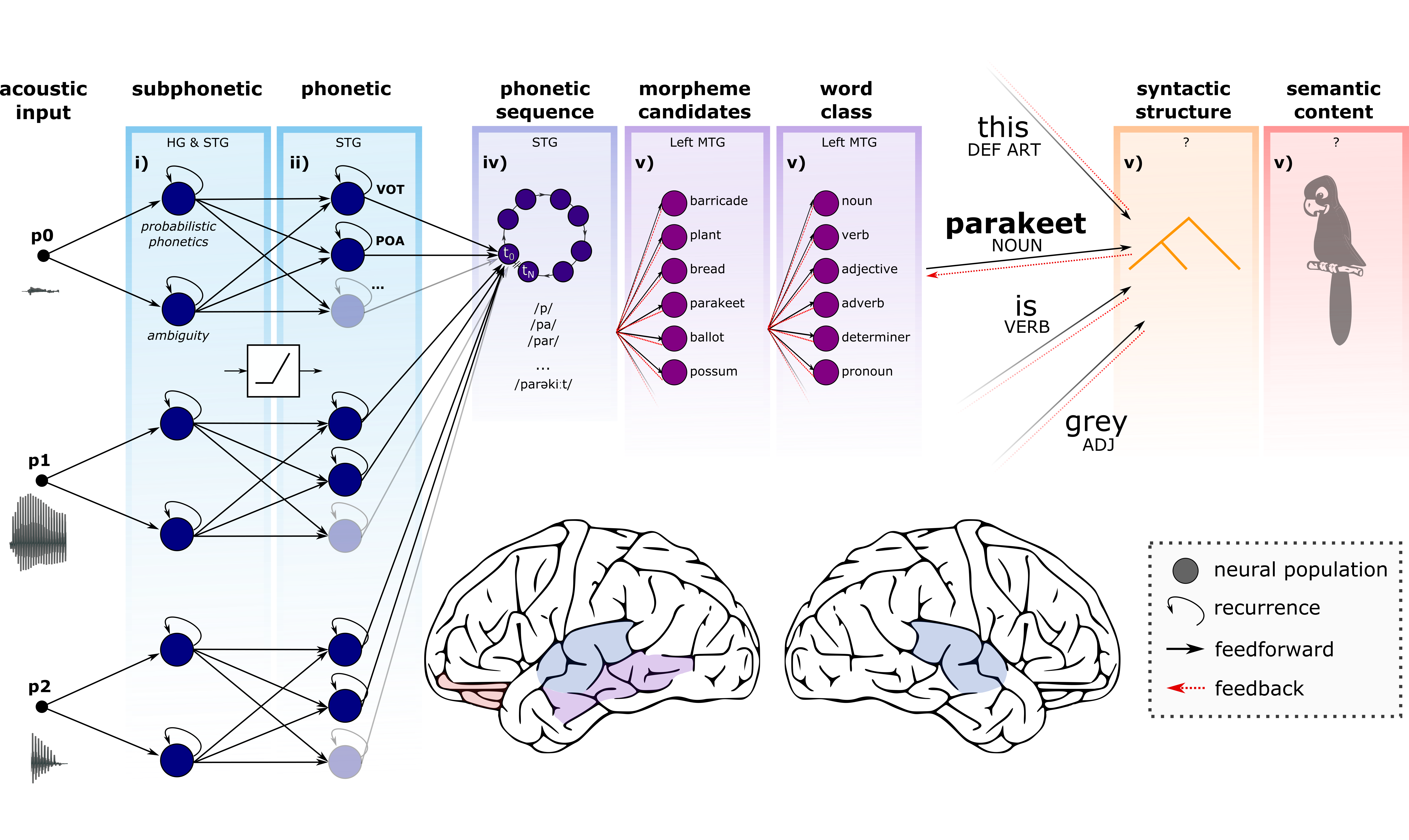
Your PhD involved a lot of research with non-invasive brain recording techniques such as EEG and MEG, but at UCSF you were also able to record speech signals in individual neurons in human research subjects. What’s different about what we can see at these different levels?
One thing I was excited to pursue during my postdoc in Eddie Chang’s lab was how the brain dynamically processes continuous speech. Speech cannot be instantaneously understood — the acoustic signal evolves over time and so do the brain’s responses.
A nice example is a study we did using machine learning to discover when the brain is processing speech sounds, those representations are not immediately discarded, but get moved between different neural populations over time. Our analysis highlighted some computational advantages of that for the brain and also showed for the first time that the brain processes this information dynamically based on the information it has. If the brain knows pretty well what the next word is going to be, it processes the speech sounds much faster than if it is uncertain what’s coming next.

Another project, which was just recently published in Nature, involved recording from single neurons in human auditory cortex using Neuropixels probes. This work is really at the frontier of the future. We’ve never before had access to 100s of individual neurons in person listening to speech, so this let us start to answer a bunch of fundamental questions. For example, how different cells are tuned — what aspects of speech each cell is sensitive to — and how the computational units of speech processing respond and communicate with one another across the layers of the brain’s cortical circuitry.
This project has really been a paradigm shift in terms of types of data we’re going to have access to moving forward. As you can appreciate, language is tricky to study partly because humans are the only ones that do it. We’ve had many decades of huge discoveries in visual neuroscience partly because of our ability to study vision in other mammals. But until very recently — such as with this new paper — we were not able to have access to that type of resolution in humans. So this could really fast-forward progress in speech and language science.
As you start your new lab at Stanford, what’s your pitch for what you’re going to tackle?
We’re going to work with brain data at different spatial scales. Some of our work is non-invasive whole brain recordings using techniques like EEG and MEG. Some uses invasive clinical recordings in epilepsy patients. Most recently we also have access to single neuron data in humans using Neuropixels probes. These are vastly different scales, from hundreds of thousands of neurons across the brain to 10s of thousands of neurons in particular regions or circuits to the micro scale of one neuron at a time.
I don’t know of any other lab that’s doing all of these techniques in one place. Unfortunately, the community using MEEG, and the community using more invasive methods to study speech networks, are not as integrated as they should or could be. I think by using both, we have a powerful way of building a theory of speech processing, mutually informed by these different techniques. People coming to the lab will be able to work with data from these different technologies, and be exposed to subfields using these different methodologies.
Looking at different levels also forces you to come up with theories that satisfy all of those spatial resolutions. If you’re analyzing single neuron data in a cortical column, you also need to relate that to what brain activity should look like at the neural population level, the local activity at the cortical surface, and across the whole brain. Any theory needs to satisfy all these levels of analysis, which gives you a better chance of developing an accurate theory.
Another thing that’s really important to me is that I’m jointly appointed between Wu Tsai Neuro, Psychology, and Data Science with a courtesy appointment in Linguistics. Linguistics is extremely helpful for deriving hypotheses about the brain’s representations of language. Data science provides powerful analysis techniques to make sense of complex neural signals and pull out information encoded subtly in minute neural responses. We’re also using large language models in our work to come up with different theories of how brain processes language: is ChatGPT doing anything similar to what the brain is doing? And of course being in psychology & the Neuroscience Theory Center at Wu Tsai Neuro will allow us to bring together neuroscientific data as well as core cognitive neuroscience theories about how all of this comes together.